Member-only story
Window Functions in SQL and PySpark ( Notebook)
Window Functions are something that you use almost every day at work if you are a data engineer. Window functions make life very easy at work. They help in solving some complex problems and help in performing complex operations easily.
let’s just dive into the Window Functions usage and operations that we can perform using them.
Note: Everything Below, I have implemented in Databricks Community Edition. This is not a written article; just pasting the notebook here. To Keep it as a reference for me going forward.
Databricks Notebook —
This notebook will show you how to create and query a table or DataFrame that you uploaded to DBFS. DBFS is a Databricks File System that allows you to store data for querying inside of Databricks. This notebook assumes that you have a file already inside of DBFS that you would like to read from.
This notebook is written in **Python** so the default cell type is Python. However, you can use different languages by using the `%LANGUAGE` syntax. Python, Scala, SQL, and R are all supported.
# File location and type
file_location = "/FileStore/tables/wage_data.csv"
file_type = "csv"
# CSV options
infer_schema = "true"
first_row_is_header = "true"
delimiter = ","
# The applied options are for CSV files. For other file types, these will be ignored.
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
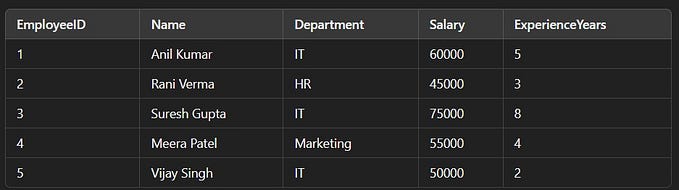
display(df)Create a view or table from the Pyspark Dataframe
temp_table_name = "wage_data_csv"
df.createOrReplaceTempView(temp_table_name)Retrieving Data from the table
select * from `wage_data_csv`With this registered as a temp view, it will only be available to this particular notebook. If you’d like other users to be able to query this table, you can also create a table from the DataFrame.
Once saved, this table will persist across cluster restarts as well as allow various users across different notebooks to query this data.
permanent_table_name = "wage_data_csv"
df.write.format("parquet").saveAsTable(permanent_table_name)There are three types of window functions:
- Aggregate — (AVG, MAX, MIN, SUM, COUNT)